Mais au fait, c’est quoi l’Open Knowledge Format (OKF) ?
Les agents d’intelligence artificielle (IA) gagnent en capacités, mais ils rencontrent toujours un obstacle majeur : la qualité du contexte fourni. Pour les relier aux outils et aux données, l’industrie a développé divers composants, du Model Context Protocol (MCP) à la Retrieval-Augmented Generation (RAG). Google a récemment introduit l’Open Knowledge Format (OKF), un standard ouvert présenté le 12 juin 2026, qui vise à représenter les connaissances d’une organisation dans un format commun à tous les agents.
Pourquoi les agents IA ont-ils besoin d’un format de connaissances commun ?
Malgré leur puissance, les modèles de langage ne comprennent pas toujours des notions spécifiques à une entreprise, comme des métriques, des schémas de données internes ou des procédures d’incidents. Ces connaissances essentielles sont souvent dispersées dans des systèmes qui ne communiquent pas entre eux, tels que des catalogues de métadonnées, des wikis, et parfois même seulement dans l’esprit de quelques ingénieurs. Par conséquent, chaque fois qu’une équipe crée un nouvel agent, elle doit reconstruire ce contexte à partir de sources disparates et incompatibles, ce qui entraîne une perte de temps et d’efficacité.
Comment fonctionne l’Open Knowledge Format ?
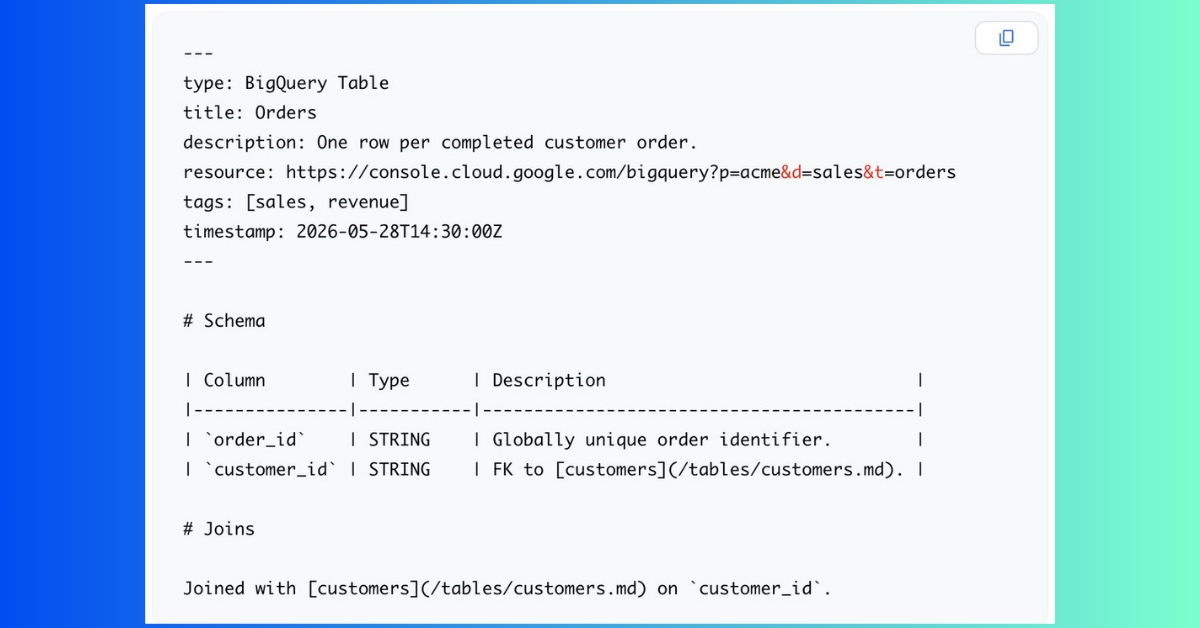
La version 0.1 de l’OKF est conçue pour être minimaliste. Elle formalise le « patron LLM-wiki », un concept qui souligne l’importance de confier la maintenance d’une base de connaissances à une IA. Concrètement, l’OKF repose sur trois principes :
- Du simple Markdown : Ce format est lisible dans n’importe quel éditeur et peut être affiché sur GitHub.
- De simples fichiers : Ces fichiers peuvent être livrés sous forme d’archives, hébergés dans un dépôt Git et accessibles depuis n’importe quel système de fichiers.
- Du YAML en en-tête : Cela permet d’interroger un petit ensemble de champs structurés, tels que le type, le titre, la description, la ressource, les tags et l’horodatage.
Chaque fichier représente un « concept », qu’il s’agisse d’une table, d’un jeu de données, d’une métrique, d’une procédure ou d’une API. Ces concepts sont interconnectés par des liens Markdown, formant ainsi un graphe de connaissances.
Pour illustrer ce format, Google a publié sa spécification sur GitHub, accompagnée d’implémentations de référence, notamment un agent capable de documenter automatiquement des jeux de données et un visualiseur HTML pour transformer une base OKF en graphe interactif.
OKF et RAG, quelle différence ?
La RAG est une technique de récupération qui cherche des documents pertinents au moment d’une requête pour les injecter dans le modèle. En revanche, l’OKF est un format de représentation qui organise les connaissances en amont. Les deux peuvent se compléter, permettant à un agent de naviguer dans un bundle OKF pour extraire uniquement les concepts utiles.
Ce que ça change pour les professionnels du digital
Bien que l’OKF cible d’abord les équipes de data et les développeurs, son impact pourrait s’étendre à d’autres domaines comme le SEO et le marketing. Les entreprises doivent désormais rendre leurs connaissances directement exploitables par des agents. Cela pourrait donner lieu à l’émergence d’une nouvelle expertise dédiée à la transformation du savoir épars en bases structurées et activables.
Cependant, l’OKF n’en est qu’à ses débuts. Google le présente comme un point de départ, susceptible d’évoluer avec les retours d’expérience. La valeur de ce standard dépendra de son adoption par un large éventail d’acteurs, et son succès nécessitera l’établissement d’un véritable écosystème de producteurs et de consommateurs.
Source : Blog du Modérateur

