Quelle IA collecte le plus de données personnelles ?
Une étude récente menée par Surfshark révèle des pratiques de collecte de données préoccupantes parmi les principaux chatbots d’intelligence artificielle. Cette analyse, basée sur les informations de confidentialité de l’App Store et les politiques des services, compare les pratiques des dix applications les plus populaires.
Une collecte de données massive et généralisée chez les chatbots IA
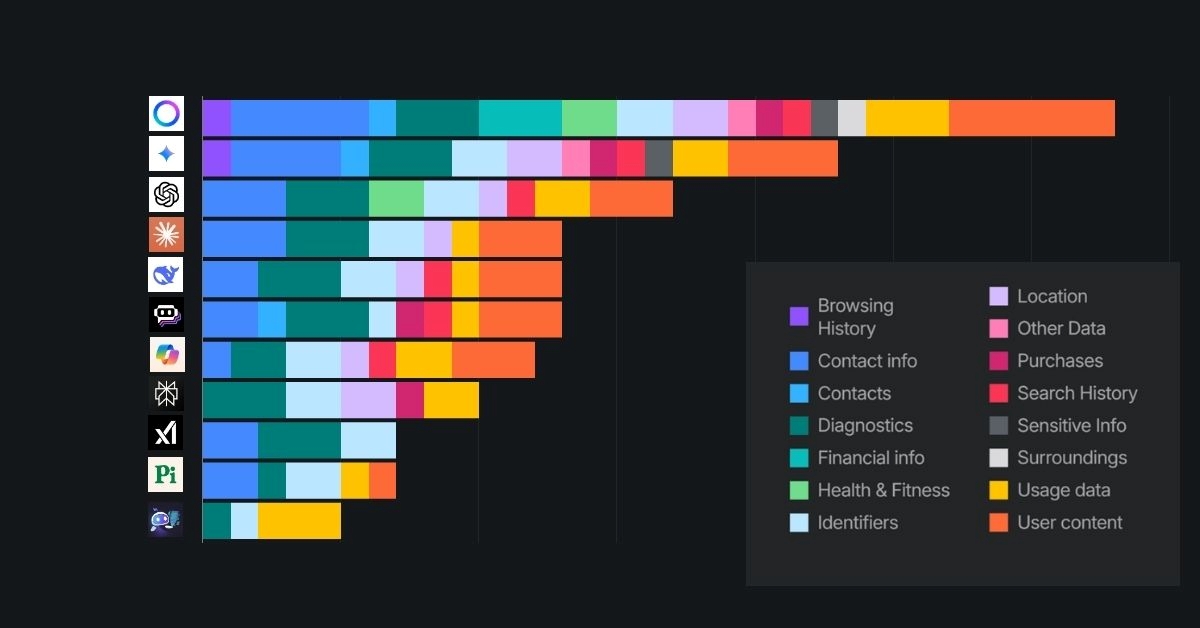
L’étude met en lumière une collecte systématique de données utilisateur par les principaux chatbots. Chaque application analysée récupère au moins un type d’information, avec une moyenne de 14 types de données collectées sur les 35 catégories identifiées. Environ 70 % des applications collectent la localisation des utilisateurs, tandis que d’autres informations telles que les coordonnées, les contenus générés, et l’historique de recherche ou de navigation sont également couramment exploitées.
Ces données ne servent pas uniquement au fonctionnement des services, mais sont également utilisées pour des analyses, de la personnalisation et du marketing. Ce niveau de collecte entraîne des risques significatifs en cas de violation de données.
Surfshark alerte : « Ne baissez pas la garde : les conversations stockées sur des serveurs restent toujours exposées à un risque de fuite. Selon The Hacker News, DeepSeek a déjà subi une violation de données ayant entraîné la divulgation de plus d’un million d’enregistrements, incluant des historiques de discussions, des clés API et d’autres informations. »
Des pratiques contrastées selon les acteurs
L’étude souligne des différences marquées entre les services. Meta AI se révèle être le plus intrusif, collectant 33 types de données sur 35 possibles, soit près de 95 % des catégories. Ce service est le seul à inclure des données financières et fait partie, avec Gemini, des plateformes qui collectent des informations sensibles, telles que les opinions politiques et les données biométriques.
En revanche, ChatGPT a élargi sa collecte de données, passant à 17 types d’informations, contre 10 lors de la précédente analyse. Les données incluent la localisation approximative, les données audio et l’historique de recherche. À l’opposé, Claude maintient une collecte plus stable, avec 13 types de données, principalement nécessaires au fonctionnement du service.
Conclusion
La collecte généralisée de données personnelles par les chatbots d’intelligence artificielle soulève des préoccupations quant à la sécurité et à la confidentialité des utilisateurs. Les différences notables entre les services mettent en lumière la nécessité d’une vigilance accrue concernant la gestion des données personnelles.
Source : Surfshark